IEEE Computer Society (April 2013)
Ubiquitous Analytics: Interacting with Big Data Anywhere, Anytime
Niklas Elmqvist, Purdue University & Fourange Irani, University of Manitoba
This article initially piqued my interest because of the subtitle: "Interacting with Big Data Anywhere, Anytime". Also, I really was not sure what Ubiquitous Analytics (Ubilytics) entailed so I was ready to expand my data science knowledge. "Ubilytics is the use of multiple networked devices in our local environment to enable deep and dynamic analysis of massive, heterogeneous, and multiscale data anytime." So, essentially, ubilytics will be able to couple the embodiment of socially distributed cognition models of human thought with novel, interactive technologies in order to harness new sources of big data and interactivity with that data. For reference, the picture below depicts how socially distributed cognition models of human thought can be visualized as a system-level process that involves the brain and 'sensors' into the physical area around a person, which includes other people and objects in addition to just space.
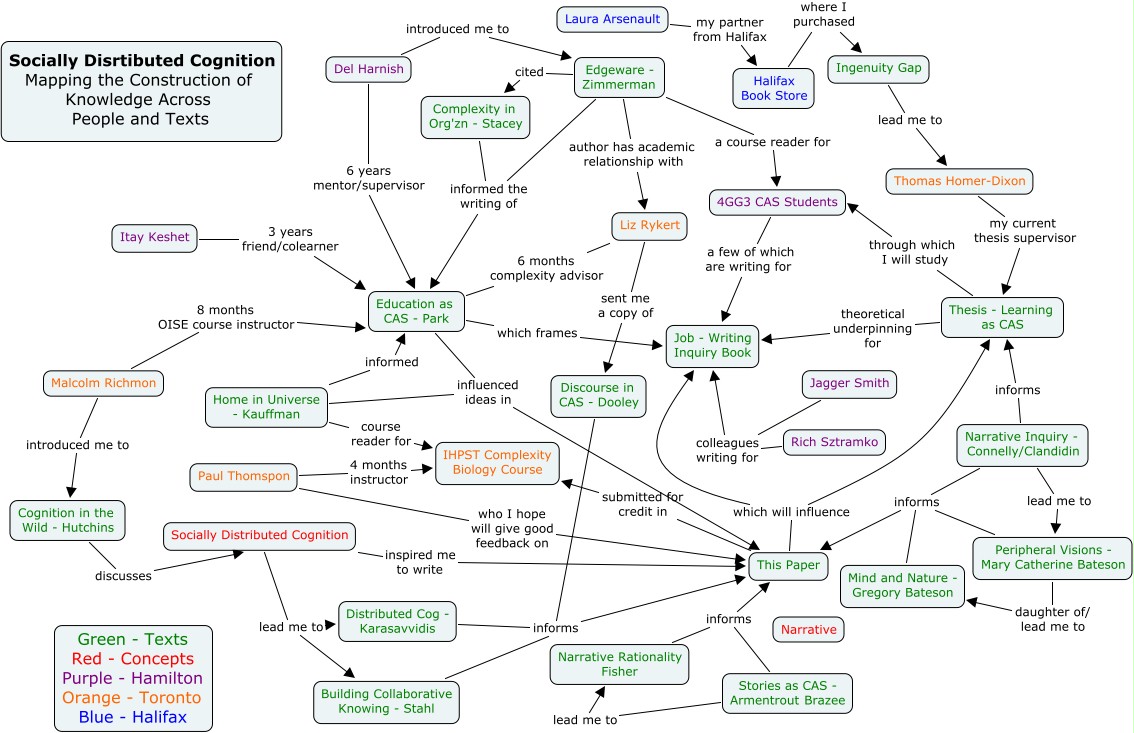 |
| Adapted from: http://photos1.blogger.com/blogger/6127/1888/1600/sdcog3.0.jpg |
Infoworld (2/6/14)
12 predictions for the future of programming
Peter Wayner
Available here
Peter Wayner is outlining predictions for how he thinks the future of programming will proceed. It is easy to predict certain aspects of the future of programming because trends are telling. For example, the first prediction he gives is that the GPU will become the next CPU. People used to brag and brag about their awesome CPU. CPU prices have dropped and GPU's have pretty much absorbed the pricing that CPU's used to have. Additionally, personal computers tend to be measured by their ability to process graphics (e.g. shading, etc.) since a lot of computers can easily get 8-16GB of RAM for cheap and i7 CPUs are almost completely mainstream for new computers. What is setting computers apart are the ability to process graphics. A lot of this is coming from personal experience so I may feel skewed, but I agree with the author here.
The next prediction is that databases will start performing more complex analyses. I completely believe this and here's why: I believe databases will start transitioning away from a rigid layout (like you would have in MySQL) when dealing with big data. For example, the concept of the semantic web is really what will take over. Being able to query data in a rdf fashion will be the future. There exist some ways on the web to query data like this. For example, dbpedia allows the querying of wikipedia through the use of SPARQL queries. I could essentially ask "What episodes of the Simpsons have the comic book guy starring" and the SPARQL query could find that data and return it to me in a quick fashion. The nature of rdf makes more sense from a cognitive perspective and really gets away from having to worry about joining tables so you can have access to all the data you need just to do some filtering. Obviously, I am a bit biased considering the nature of my primary field of study, but I do wholeheartedly believe that this is a true prediction.
The next few predictions I cannot really take a firm stance on because I am not as well versed in the fields. Peter Wayner says Javascript will take over and I can kind of see how that may happen for all the reasons that he elicits (I also have a Chromebook that runs Chrome OS). I don't see lightweight OS's such as this becoming fully mainstream, but there is a viable market for them, especially for the utilization of cloud-based technologies. Additionally, Peter Wayner says Android will take over and essentially be involved with everything technologically. I can see this happening just as easily as I can see it failing. Integrating lightweight, mobile technologies just makes sense. The Android platforms can already be used as universal remotes. What is there to stop Android from becoming a more widely-available and universal standard?
The rest of the predictions feel more as a trend-following than bold predictions. For example, open source technologies are only going to grow as the computer science communities seem to only be amicable toward open source. Additionally, the command line will always prevail when it comes to scripting. A GUI is just a dumbed down (another topic tackled by Peter Wayner) version of the command line - and dumbed down is really just another way to say "abstracted beyond full usage" here. Lastly, there will always be a disconnect between managers and computer scientists when it comes to projects. Until we embrace computer science as a stringent requirement in schooling, it will remain this way. Even then it still will not be perfect. Overall, I enjoyed Peter Wayner's article because it really puts the programming and software engineering world in perspective with the upcoming years.
Lastly, I would like to reach back to Opensource.com for an article.
http://opensource.com/business/14/2/analyzing-contributions-to-openstack
This article is about one writer's experience whenever asking 55 contributors to openstack why they only contributed once in the past year. What reasons or lack of reasons were there and what could make them want to contribute more, if anything. The top 3 reasons that were given as to why they do not contribute more can be traced back to their primary usage of openstack. Developers of openstack were a large amount of the people that were surveyed. Another portion were people that secondarily use openstack with their own projects. Last, there was a group who deployed openstack for utilization by their own customers. So what was stopping them from contributing further? You would think that they would love to keep patching bugs to help themselves, their customers, and the community in general. Well, as aforementioned, there are 3 top reasons cited as to why they only contributed once in the past 12 months:
1) Legal hurdles - a lot of contributors had NDAs that would stop them from contributing as they would be in violation. Additionally, some companies that these people worked for had instituted corporate policies that prevented them from contributing.
2) The length of time it takes for contributions to actually be reviewed and accepted.
3) Simple bugs just are not around long enough for a contribution to be made without it taking a very long amount of time.
Now I can very much see the number 2 and number 3 hurdles (I've never been in a situation where legal blocks have impeded me) being very prevalent. In Galaxy, for example, the core developers are so active that they tend to patch smaller bugs very quickly and a lot of the bugs or feature requests that are still around are usually very large implementations or it would take reworking of core parts of the environment that the developers are unsure of how they want tackled.
Now that I've tackled all of the articles that I wanted to review, I am going to be going through some exercises out of Chapter 7 of Teaching Open Source.
The first exercise is essentially finding the difference between running a diff command on its own and diff with a "-u" flag. That flag changes the output of the diff into a unified format, which is usually the accepted standard for sending diffs to other developers. The next exercise focuses on using diff whenever submitting a patch. Well, whenever I submitted my team's patch to Bitbucket, we had to run a diff. There's a link to it in my past post's pull request. Diffs are awesome for showing changes like that. Additionally, I ran a diff from within Mercurial whenever trying to figure out how to get my branches merged together. Lastly, there was an exercise that wanted me to patch echo so that it would print arguments out in reverse order. This was a trivial exercise that really just required the use of a for-loop and knowing how to reconfigure and perform a make on the file.
Music listened to while blogging: N/A - Watching @Midnight on Comedy Central
No comments:
Post a Comment